
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코드프렌즈
- 토익
- 데이터분석
- 데이터관련자격증
- minerva university
- toeic
- 토익문제
- 토익문법
- ai consensus
- TOPCIT
- students@ai seoul hackathon
- ai공모전
- ADsP
- 논문 pdf 이름
- 탑싯
- OpenCV
- scaico
- 논문 pdf
- 탑싯시험
- 미네르바 대학
- IT자격증
- 프론트
- 토익공부
- 환급형프론트챌린지
- pdf 다운로드
- pip
- 토익공부법
- 크롬 확장프로그램
- cv2
- arXiv
- Today
- Total
토리의 데굴데굴 공부일기
[ 논문리뷰 ] Attention Is All You Need - 2017 본문
https://arxiv.org/pdf/1706.03762.pdf
0. Abstract
지배적인 sequence transduction 모델들은 인코더와 디코더를 포함한 복잡한 RNN 혹은 CNN에 기반하고 있다. 가장 성능이 좋은 모델들도 인코더와 디코더를 attention 기법으로 연결하고 있다. 이 논문에서는 새로운 단순한 네트워크 구조인 Transformer를 제안한다. Transformer는 오직 attention 기법만을 기반으로 하고 있다. 두개의 기계 번역 task는 이 모델들이 병렬화가 가능하고 학습에 소요되는 시간이 현저히 적지만 최고의 성능을 가진다는 것을 보여준다. WMT 2014 English-to-French 번역 task에서는 new single-model SOTA를 달성함. (BLEU score 41.8, 8개의 GPU로 3.5일동안 학습시킴) Transformer는 일반적으로 다른 task들에도 잘 적용될 수 있고,크고 제한적인 training data에서도 잘 작동한다.
해당 논문은 Non-recurrent sequence to sequence encoder-decoder model을 만드는 것이 목표이다.
1. Introduction
RNN, LSTM, gated RNN은 sequence modeling과 transduction problem의 SOTA로 자리잡았다. (예를 들어 언어 모델링, 기계번역) RNN 모델과 인코더-디코더 구조의 경계를 확장하려는 노력은 계속되었다.
Attention 이전의 RNN, LSTM, Seq2Seq 모델은 고정된 크기의 context vector를 사용하지만, Attention 이후의 Transformer 모델들은 입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전했다.
Sequence Modeling

Sequence modeling은 어떠한 Sequence를 가지는 데이터로부터 또 다른 Sequence를 가지는 데이터를 생성하는 task이다. 대표적인 예로는 machine translation, chatbot 등이 있다. 위 이미지는 터키어로 쓰인 문장을 sequence model에 입력하여 영어로 번역된 문장이 나오도록 하는 예시이다.

이러한 Sequence modeling에는 대부분 RNN,LSTM,GRU가 주축으로 사용되었는데 몇몇 문제들이 발생했다. 위와 같은 Recurrent model들은 모든 데이터를 한꺼번에 처리하는 것이 아니라 sequence position t에 따라 순차적으로 입력을 넣어주어야 한다. 예를 들어 i am ironman을 Recurrent model에 넣을 때, 먼저i를 network에 넣고 산출되는 hidden state h_t를 다음 position인 am에 대한 hidden state h_t+1를 계산할 때 사용한다. 이러한 한계는 긴 sequence 길이를 가지는 데이터를 처리해야 할 때, memory와 computation에서 많은 부담이 생기게 된다.
Attention mechanism

attention이라는 mechanism은 이 논문에서 처음 나온 것이 아니다. 이미 Sequene modeling에서 널리 사용되고 좋은 성능을 보이는 기법이었다. attention은 input 또는 output 데이터에서 sequence distance에 무관하게 서로 간의 dependencies를 모델링한다. 예를 들어, 위 이미지는 french를 english로 번역하는 sequence modeling에서 attention을 사용했을 때 그 correlation matrix를 나타낸다.
논문에서 제안한 Transformer는 이러한 Attention mechanism을 전적으로 사용하여, 아예 모든 Network Architecture를 Attention만으로 구축하고 이의 효율성과 엄청난 성능을 실험을 통해 보여준다.
Sequence-to-Sequence

논문에는 나와 있지 않지만 Transformer의 장점을 소개할 때 Sequence-to-Sequence method가 종종 등장한다. Seq2Seq는 위와 같은 architecture를 가지고 있다.
이전에 설명했듯 Recurrent model은 Sequence 순으로 데이터가 입력되는데, 이전 데이터의 hidden state h_t가 다음 데이터의 hidden stateh_t+_1를 구할 때 사용된다. 즉, 어떠한 시점 t에서 구한 hidden state h_t는 그 전 sequence들의 정보를 함축하고 있다고 볼 수 있다.
따라서 위 이미지를 예로 들어 설명하면, tomorrow를 입력으로 받아 출력되는 encoder의 마지막 hidden state는 그 이전 단어들(are,you,free)에 대한 정보까지, 즉 문장의 모든 단어들에 대한 정보를 함축하고 있는 것이다.
Seq2Seq 모델은 이 encoder의 최종 output을 일종의 embedded vector로 사용하여 decoder에 넣어주게 되는데, 이때 memory와 computation 때문에 embedded vector의 max length를 제한해야 한다. 긴 sequence 데이터를 처리해야 할 때, 제한된 크기의 vector로 모든 정보를 담아내야 하기 때문에 정보의 손실이 커지고 이에 따라 성능의 병목현상이 일어난다.
이러한 문제를 완화하기 위해 encoder의 모든 state를 decoder에 참조시키거나 attention을 적용하는 등의 여러 시도가 있었는데, 그 중에서 가장 효과적이고 강력한 방법이 바로 이 Transformer였다.
2. Model Architecture

좋은 성능을 보이는 Neural sequence transduction model들은 대부분 encoder-decoder 구조를 가지고 있다. transformer 또한 이 구조를 따라가고 있고, 그 내부는 self-attention과 FC layer만으로 구성되어 있다.
2.1 Attention

이 논문에서는 Scaled Dot-product Attention과 Multi-Head Attention 두가지 방식의 Attention 기법을 사용한다.
Scaled Dot-Product Attention
먼저 input으로 Query(Q), Key(K), Value(V) 총 3개가 들어온다. 여기서 Query는 물어보는 주체, Key는 반대로 Query에 의해 물어봄을 당하는 주체, Values는 데이터 값들을 의미한다.
Attention(Q,K,V) = softmax(QK^T\sqrt{d_k}V)
식을 하나씩 살펴보자. 여기서 Query q는 어떤 단어를 나타내는 vector이고, K는 문장의 모든 단어들에 대한 vector들을 stack해놓은 matrix이다.
**Q와 K는 차원이 같기 때문에 d_k dimensions, V는 d_v dimensions을 가진다. 논문에서는 d_k=d_v 로 두고 사용한다.

예를 들어, AI is awsome이라는 문장에 attention을 적용해보자. 위에서 Query는 awsome, 그리고 key는 모든 단어들의 stacked matrix이다. 여기서 QK^T는 한 단어(q:awsome)와 모든 단어(K: AI, is, awsome)들의 dot product를 해줌으로써 어떠한 relation vector를 만들어낸다. 이를 모든 단어를 query로 사용할 때까지 반복한다.
**실제로는 query를 key와 같이 stack해서 matrix와 matrix간의 dot product를 통해서 relation matrix를 만든다.
가장 흔히 쓰이는 attention functions으로는 additive attention과 dot-product attention 두가지가 있다. 두 방법은 이론적인 complexity는 비슷하지만, dot-product 방식이 매우 최적화된 matrix multiplication code로 구현될 수 있어 더 빠르고 공간효율적이라서 이를 채택했다고 한다. 여기서는 기존 방식과 다르게 1/\sqrt{d_k} 로 scaling을 해주는데, 이를 해주지 않으면 additive attention보다 성능이 대폭 떨어진다고 한다. 논문에서는 이를 softmax가 0 근처에서는 gradient가 높고, large positive and large negative value들에 대해서는 매우 낮은 gradient를 가지기 때문에 학습이 잘 되지 않는 문제가 일어나고, scaling을 통해 모든 값들이 0 근처에 오도록 만들어줌으로써 이러한 문제를 해결한다.
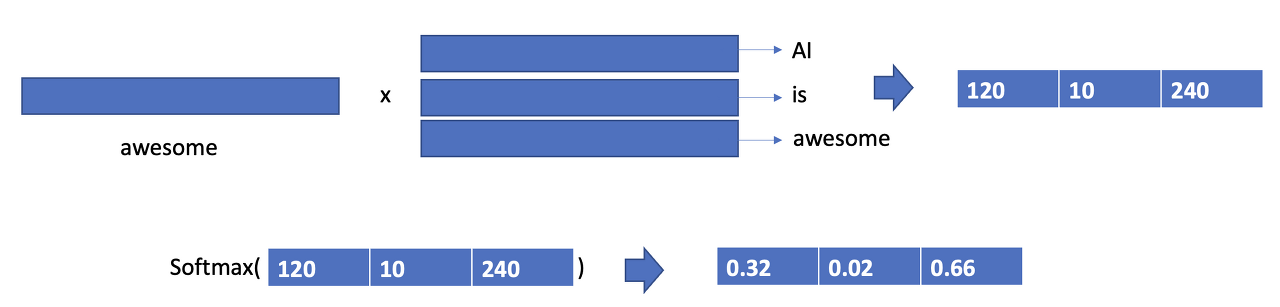
마지막으로 softmax를 통해서 Query 단어가 모든 단어들과 어느정도의 correlation이 있는지를 확률 분포 형태로 만들고, 이를 value matrix와 dot product를 해줌으로써 기존 vector에 Query와 Key간의 correlation 정보를 더한 vector를 만든다.
**encoder의 경우: Query, Key, Value가 모두 입력 단어들임
**decoder의 “encoder-decoder attention”의 경우에는 Key와 value는 encoder의 output이 되고, query가 decoder의 입력 단어들이 됨
옵션으로 Mask layer가 있는데, 이는 참조하고 싶지 않은 correlation을 masking할 때 사용된다.
**Padding mask: 패딩되어진 값들은 참조하면 안되니까 masking함
**Look ahead mask: 미래 시점의 단어가 attend하지 않도록 making하는 것
(RNN은 입력을 순차적을 받기 때문에, 현재 시점의 단어를 예측할 때 이전에 입력되었던 단어들만 attend할 수 있다.
하지만, Transformer는 문장 행렬을 한번에 받기 때문에 현재 시점의 단어를 예측할 때 미래 시점의 단어들도 attend 할 수 있는 현상이 일어난다.
따라서 미래 시점의 단어가 attend 하지 않도록 마스크를 씌워야 한다. 이를 look-ahead mask라 한다.)
Multi-Head Attention
한 input을 여러개의 head를 만들어서 똑같이 attention을 수행하여 feature representation의 variation을 만드는 방법
하나의 attention function을 사용하는 것보다, queries와 keys,values를 linear projection을 통해 중간에 매핑해줘서 각 다른 값들을 입력으로 하는, 여러 개의 attention function들을 만드는 것이 더 효율적이라고 한다. 나중에 function의 출력들은 concatenate되고 다시 linear function을 통해 매핑한다. 이러한 기법은 CNN이 여러개의 필터를 통해서 convolution output을 구하는 것과 비슷한 효과를 보일 것이다.
https://velog.io/@aqaqsubin/Transformer-Attention-Is-All-You-Need
https://aistudy9314.tistory.com/63
'ML DL > 2023 KHU AI Track' 카테고리의 다른 글
| [ 논문 리뷰 ] Generative Adversarial Networks(GAN) (0) | 2023.08.09 |
|---|---|
| [ 논문 리뷰 ] AlexNet: ImageNet Classification with Deep Convolutional Neural Networks (0) | 2023.08.02 |
| Foundation of Artificial Intellegence (0) | 2023.07.30 |


