
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- model collapse
- 데이터관련자격증
- 토익공부
- ADsP
- 아이엘츠
- 논문 pdf 이름
- students@ai seoul hackathon
- 코드프렌즈
- 크롬 확장프로그램
- toeic
- 토익문법
- 토익문제
- 데이터분석
- 토익
- 탑싯시험
- scaico
- ai model collapse
- 논문 pdf
- 환급형프론트챌린지
- TOPCIT
- ai consensus
- minerva university
- 토익공부법
- cv2
- 탑싯
- pip
- arXiv
- 미네르바 대학
- ai공모전
- pdf 다운로드
- Today
- Total
토리의 데굴데굴 공부일기
[ 논문리뷰 ] Pixel Recurrent Neural Networks (PixelRNN, PixelCNN) 본문
Pixel Recurrent Neural Networks
0. Generative Modeling
- unsupervised learning의 일종
- pixel들의 확률 분포를 추정 (density estimation)
1. Density Estimation
1.1. Explicit density estimation
- Tractable density : PixelRNN / PixelCNN
- Approximate density : VAE
1.2. Implicit density estimation
- Direct : GAN
- Stocastic : GSN
2. Pixel - by - pixel Image Generation
- density를 tractable 하게 실제로 modeling
- image가 주어졌을때 그 이미지들을 만들어내는 확률분포 p(x)를 명시적으로 구하는 방법
- RNN처럼 앞자리까지 만들어낸 pixel들을 바탕으로 다음 pixel값을 예측함
- image는 RGB 3개의 채널로 구성되어 있어 RGB 순서대로 만들어냄
3. 구현 (3가지 방법)
3.1. Row LSTM
- hidden state + input => 예측값
- RNN처럼 pixel을 하나하나 순차적으로 만들어냄 (RNN 개념, but 구현은 Conv로 함)
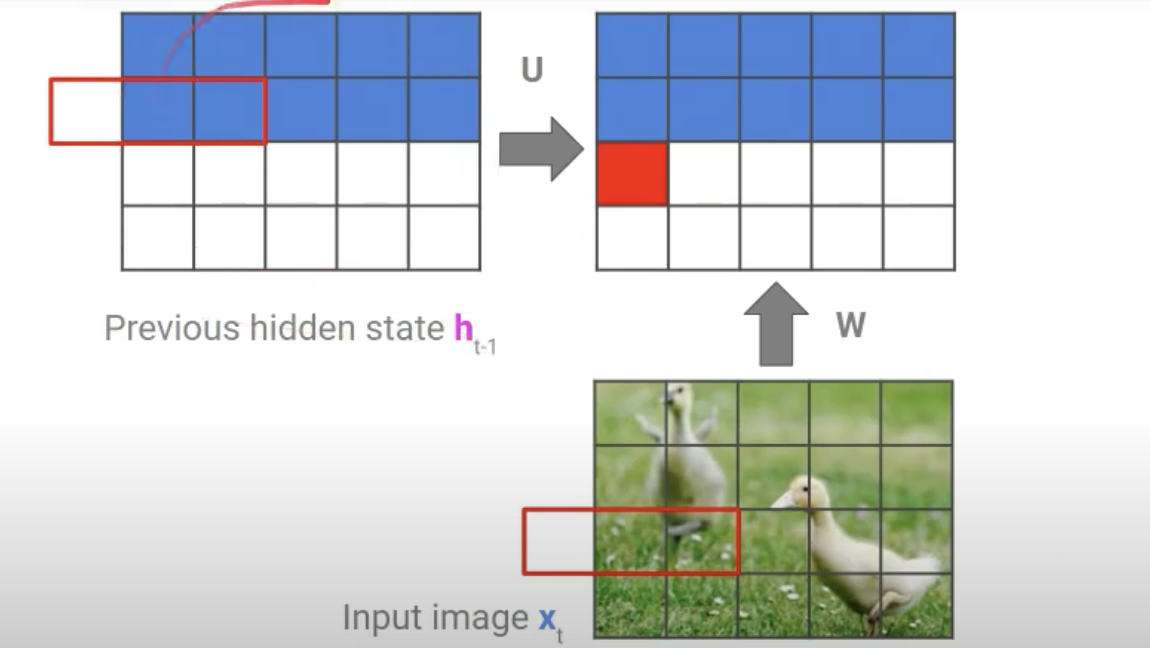
- 위 사진처럼 하나의 픽셀을 만들때 그 윗줄의 3개의 pixel을 참고함
- 하지만 이렇게 할 경우 위 사진처럼 하나의 pixel을 만들때 그 위의 역삼각형 모양의 receptive field만 보게되어 만들어진 모든 pixel들을 참고하지 않는다는 단점이 발생함
장점: 한 픽셀씩 recurrent하게 image를 생성할 수 있다 (image generation의 시초가 되었다는 의의를 가짐)
단점: receptive field가 앞에서 만들어낸 전체 pixel이 아님
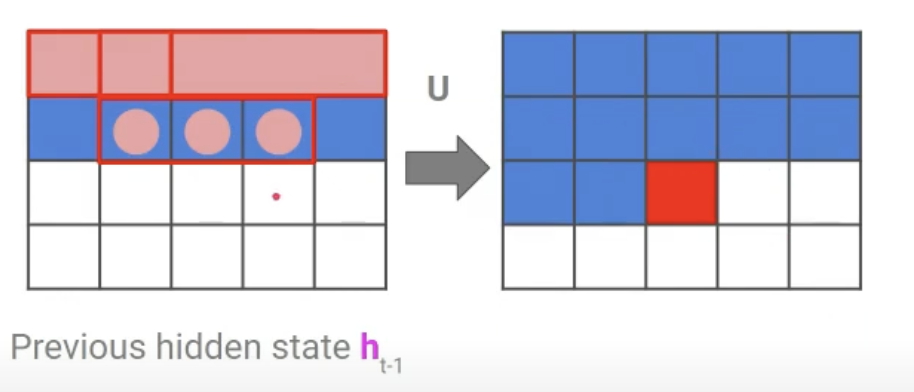
3.2. Diagonal BiLSTM
- 위의 Row LSTM의 단점을 극복하고자 고안됨.

- 윗줄의 픽셀을 보는 것이 아닌 위 사진처럼 만들고자 하는 픽셀의 왼쪽과 위쪽의 픽셀 2개만을 참고함.
- 이렇게 하면 결과적으로 하나의 픽셀을 만들때 이전에 만들었던 모든 픽셀을 참고할 수 있음

- 구현의 효율화를 위해 skewing이라는 기법 활용. 이렇게 한칸씩 픽셀을 다 밀면 참고하는 픽셀을 2x1 kernel로 처리 할 수 있음
- parallel하게 돌릴 수 있어 구현이 쉬움 (implementation trick)
- 그리고 이걸 오른쪽 대각선과 왼쪽 대각선 두가지 방향을 반복하여 양쪽 패턴을 동시에 볼 수 있도록 함
장점: receptive field가 전체 영역이 됨
단점: 속도가 느림
3.3. PixelCNN
- 어차피 위의 것들도 구현할땐 Conv로 구현했으니, 아예 CNN으로 접근해보자!

- 위 그림처럼 참고하는 영역의 pixel 부분의 Conv kernel만 1로 두고, 나머지는 0으로 둔 채 Conv layer를 거치는 방식
- 특수한 크기(3 x 3)의 Convolution mask filter를 사용해 작업
장점: PixelRNN보다 Training 시에 속도가 빠름
단점: 모델이 특정 시점 이전의 일부 데이터를 활용하지 못하는 Blind spot 문제가 발생하는 문제점 존재 (사각지대 존재)
4. 후속연구
Gated Pixel CNN



