[ 논문리뷰 ] ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)
https://arxiv.org/pdf/2010.11929
Introduction
NLP domain에서 시작된 Transformer를 CV domain으로 적용해 처음으로 큰 성과를 얻은 논문이 ViT이다.
Transformer 아키텍쳐가 NLP domain에서는 거의 표준처럼 사용이 되고 있었지만, 이를 CV domain에 적용시키는 것은 한계가 있었다.
CV는 원래 CNN이 지배적인 분야였기 때문에 CNN과 self-attention을 결합하려는 다양한 시도들이 이루어졌지만, scalability를 가지진 못했다.
**scalability: 모델의 사이즈(용량)이 커질수록 성능도 그에 비례해 높아지는 특성
하지만 ViT(Vision Transformer)는 CNN을 사용하지 않고 transformer의 인코더 부분에 직접적으로 image patch sequence를 넣는 방식을 사용한다. 이 ViT는 특히 image classification task에서 잘 작동한다.
큰 용량의 데이터셋(ImageNet, CIFAR-10 등)에서 pre-trained되어 다른 downstream task들로 transfer되는 경우에는
- ViT는 기존의 CNN기반 SOTA 모델들보다 훨씬 좋은 성능을 가진다.
- 그리고 ViT는 Fine-tuning training 과정에서 훨씬 적은 computation resource를 필요로 한다.
- Patch-based Approach 사용, self-attention mechanism 사용
Method

Input Embedding
NLP에서 사용되는 일반적인 Transformer와 ViT의 가장 큰 차이점은 ViT는 입력 이미지를 patch 단위로 쪼개 입력 임베딩으로 사용한다는 점이다. Patch 단위로 쪼갠 image들을 Linear Projection을 통해 Flatten Patches로 만든다. 이렇게 만든 patch embedding에 patch가 이미지의 어느 위치에 있던 것인지 그 위치정보를 표현하는 Position Embedding을 더해 최종 Input Embedding으로 사용한다. 이때 가장 앞쪽에 있는 *는 추가적인 learnable [class] token이다. 이는 classification을 위해 추가된 학습가능한 token이다.
다시 정리하자면 NLP domain의 Transformer는 input을 token 단위로 나눠 token embedding을 사용하고, CV domain의 Transformer는 input을 patch 단위로 나눠 patch embedding을 사용한다는 점이 가장 큰 차이점이라 할 수 있다.
Transformer Encoder


(좌) ViT (우) Transformer
이렇게 만들어진 input embedding은 Transformer Encoder로 들어가게 된다. 먼저 normalization을 거치고, multi-head attention을 거치고, residual을 더해준다. 다시 normalization을 거치고, MLP를 거치고 residual을 더해줘 출력값을 만든다.
ViT에서는 기존 transformer와 normalization 위치가 달라졌는데, 기존에는 attention을 하고 normalization을 하는 방식이었지만 여기서는 normalization을 한 후 attention을 수행한다.
Classification
classification 수행을 위해 Transformer encdoer에서 나온 출력값은 MLP head로 들어가 class를 예측하는 작업을 수행한다. 이 과정을 거치면 입력된 사진이 어떤 class에 속하는지 분류할 수 있게 된다.
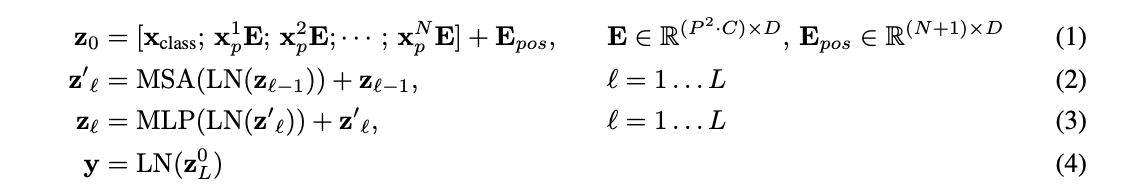
수식으로 다시 살펴보자면
먼저 첫째줄 z_0는 입력에 해당하는 수식이다. x_class는 classification token이다. XNpE는 patch로 나눈 각각의 이미지 시퀀스이다. 마지막으로 E_pos는 각각의 시퀀스의 poistion embedding을 나타낸다.
둘째줄 z'_l은 Transformer Encoder에 해당하는 수식이다. 이전 값을 Layer normalization한 후에, Multi-head attention을 적용한다. 해당 값에 skip connection을 더해준다.
셋째줄은 MLP head에 해당하는 수식이다. 윗부분의 수식과 같은 연산을 하고, MLP head를 거친다.
넷째줄은 출력값을 만드는 부분인데, 마무리로 나온 학습 0번째 출력값 z(cls token)을 layer normalization하여 classification을 수행한다.