
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- ai model collapse
- model collapse
- 아이엘츠
- 탑싯
- ai consensus
- 토익문법
- arXiv
- 크롬 확장프로그램
- toeic
- 토익문제
- 토익공부법
- scaico
- ADsP
- 논문 pdf 이름
- 논문 pdf
- students@ai seoul hackathon
- 토익
- ai공모전
- minerva university
- 데이터관련자격증
- 탑싯시험
- 데이터분석
- cv2
- 미네르바 대학
- 환급형프론트챌린지
- pip
- 코드프렌즈
- TOPCIT
- 토익공부
- pdf 다운로드
- Today
- Total
토리의 데굴데굴 공부일기
[ ML/DL ] Loss function 왜 필요하고, 어디에 사용되는 걸까? 본문
(KHUDA CV트랙 1주차 발표 내용)
Loss function
Loss function (손실 함수) = Cost function (비용 함수) = Objective function (목적 함수)
❓ Loss function은 왜 필요하고, 어디에 사용하는 걸까요?

우리가 ML / DL 모델을 모델링하면 우리가 만든 모델은 예측값을 출력합니다. 예측값을 한번 출력하고 끝나는 것이 아닌, 최대한 모델의 예측값이 실제값과 같도록 이를 최적화시키는 과정을 거쳐야 합니다. 이때 모델의 예측값과 실제값 사이의 오차를 비교하기 위한 기준을 Loss function이라고 합니다. 따라서, Loss function은 머신러닝, 딥러닝 모델 학습에서 필수 구성요소라고 할 수 있습니다.
손실함수로 인해 모델의 성능이 달라질 수 있고, 이러한 이유로 머신러닝 모델을 구현하는 사람들은 어떠한 손실함수가 최적일지 고민하는 과정이 필요합니다.
손실함수는 데이터 형식에 따라 조금씩 달라집니다.

- 수치형 데이터: 회귀 분석
- 범주형 데이터: 분류 분석
1. 회귀 모델
1-1. MAE (평균절대오차)

- 미분 불가능
- 정답값과 예측값 차이에 대한 절대값의 평균
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y, y_pred)
1-2. MSE (평균제곱오차)

- 미분 가능
- MAE에서 절댓값을 제곱으로 바꾼 것
- 제곱을 하기 때문에 이상치에 민감함
from sklearn.metrics import mean_squared_error
mean_squared_error(y, y_pred)
2. 분류 모델
2-1. Cross Entropy → 정보이론 공부 필요
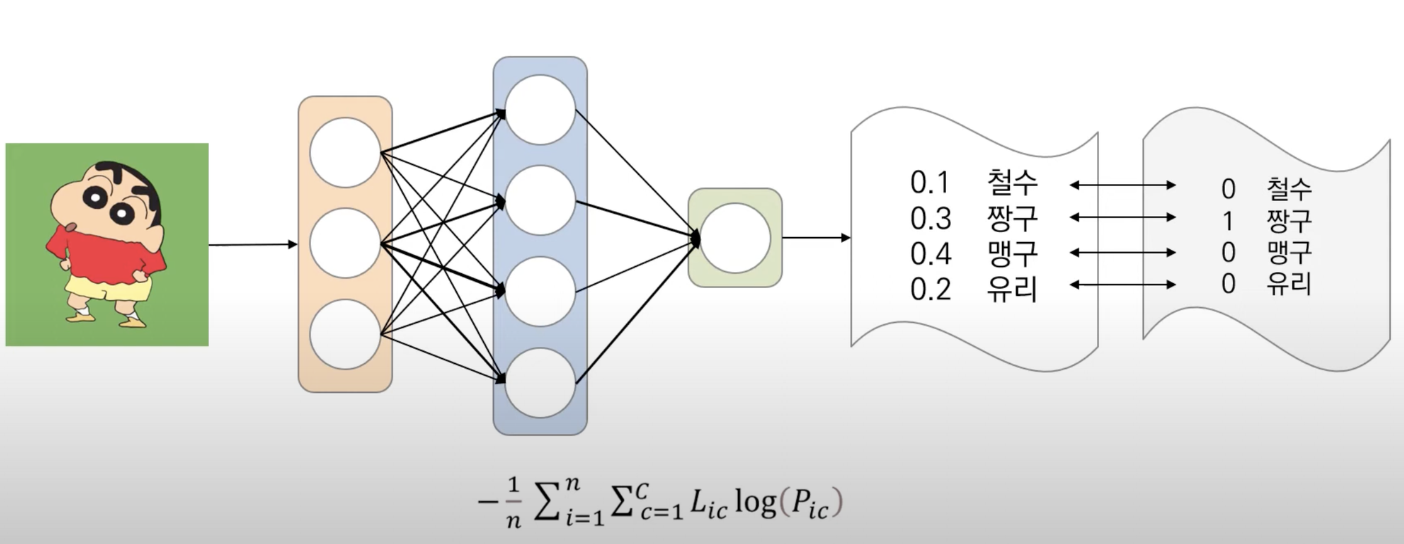
- Entropy : 정보를 표현하는데 필요한 최소 평균 자원량
- Cross-Entropy
- KL Divergence
❓ 그럼 그 최적의 손실함수는 어떻게 찾는데?
경험적 탐색
- 데이터, 분야에 따라 자주 쓰이는 Loss function을 사용
- sklearn, pytorch에서 제공되는 Loss function 사용
- 제공되는 Loss function을 수정하여 사용
- 직접 Loss function을 제작하여 사용
Adaptive Loss Function
- A General and Adaptive Robust Loss Function
- 데이터 분포에 따라 적응하여 손실함수가 변화하는 방식
https://arxiv.org/abs/1701.03077
A General and Adaptive Robust Loss Function
We present a generalization of the Cauchy/Lorentzian, Geman-McClure, Welsch/Leclerc, generalized Charbonnier, Charbonnier/pseudo-Huber/L1-L2, and L2 loss functions. By introducing robustness as a continuous parameter, our loss function allows algorithms bu
arxiv.org
AM-LFS : AutoML for Loss Function Search
- 강화학습을 이용하여 학습과정에서 최적의 손실함수를 찾는 방식
- Optimizer는 Adam으로 고정 후 초기화 된 모델과 분포를 통해 최적의 모델을 도출
https://arxiv.org/abs/1905.07375
AM-LFS: AutoML for Loss Function Search
Designing an effective loss function plays an important role in visual analysis. Most existing loss function designs rely on hand-crafted heuristics that require domain experts to explore the large design space, which is usually sub-optimal and time-consum
arxiv.org
Reference
http://dmqm.korea.ac.kr/activity/seminar/326
고려대학교 DMQA 연구실
고려대학교 산업경영공학부 데이터마이닝 및 품질애널리틱스 연구실
dmqa.korea.ac.kr
'ML DL' 카테고리의 다른 글
| 3D Representation 정리 (Mesh, Point Cloud, NeRF, 3D Gaussian) (4) | 2025.07.31 |
|---|---|
| <Do it! 데이터 과학자를 위한 실전 머신러닝> 후기 (0) | 2023.08.31 |
| 분류모델 평가산식 정리(Accuracy, Precision, Recall, F1-score) (0) | 2023.06.29 |
| 이미지 생성 AI 모델 소개(VAE, GAN, Diffusion Models) (0) | 2023.06.27 |



