
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 논문 pdf 이름
- model collapse
- 데이터관련자격증
- 미네르바 대학
- 토익
- 데이터분석
- arXiv
- pdf 다운로드
- pip
- 토익공부
- 토익문제
- ai consensus
- minerva university
- 탑싯
- ADsP
- 크롬 확장프로그램
- TOPCIT
- 토익문법
- students@ai seoul hackathon
- 아이엘츠
- ai model collapse
- 코드프렌즈
- ai공모전
- cv2
- scaico
- toeic
- 환급형프론트챌린지
- 논문 pdf
- 탑싯시험
- 토익공부법
- Today
- Total
토리의 데굴데굴 공부일기
이미지 생성 AI 모델 소개(VAE, GAN, Diffusion Models) 본문
Generative Model이란?
In Google Developer..
- Generative model can generate new data instance. //새로운 data instance를 생성할 수 있다.
- Discriminative models discriminate between different kinds of data instances. //Discriminative model은 data instance를 종류에 따라 나눌 수 있다.
- Generative models capture the joint probability p(X,Y), or just p(X) if there are no labels. //Generative models은 확률분포를 포착한다.
Generative Model이란 결국 새로운 data instance를 생성해내는 모델이다. 여기서 '생성'이란 단순히 Data Instance를 생성하는 것이 아닌 Training Data의 Distribution을 근사하는 특성을 가지고 있다.
예를 들어 강아지, 고양이의 이미지 데이터를 Generative Model의 입력으로 준다면 우리는 입력 데이터와 상당히 유사한 분포(distribution)을 갖는 새로운 이미지 데이터를 얻게 된다.

AE & VAE
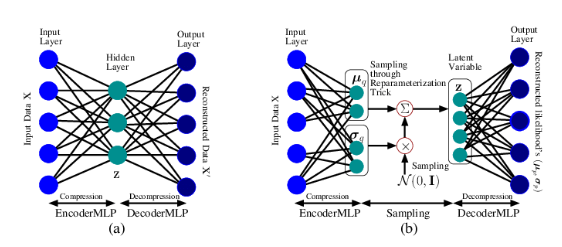
AE(AutoEncoder)와 VAE(Variational AutoEncoder)는 수학적으로 전혀 관계가 없다.
AutoEncoder의 목적은 Manifold Learning이다.
- AE는 네트워크의 앞단을 학습하기 위해 뒷단을 붙인 것이다.
- 입력 데이터의 압축을 통해 데이터의 의미있는 manifold를 학습한다.
Variational AutoEncoder는 Generative Model이다.
- 뒷단(Decoder, 생성)을 학습시키기 위해 앞단을 붙인 것이다.
- 그런데 공교롭게도 그 구조를 보니 AE와 같다.
- VAE는 Generative Model이다!

VAE: Variational AutoEncoder
VAE는 기본적으로 인코더-디코더의 Autoencoder 구조로 되어 있다. 입력 이미지의 실제 분포 P는 다양하고 다루기 어려운 복잡한 분포를 가지는 경우도 많다. 이러한 상황에서 VAE는 P에 근사하는 (우리가 다루기 쉬운 확률 분포)Gaussain 등의 분포 Q(μq,σq)를 가정하고 이를 찾는 방식으로 학습을 진행한다.
Q를 가우시안으로 가정하면 인코더는 분포 Q의 평균과 분산을 찾아 latent variable z를 추출하고, 디코더는 z로부터 x를 복원한 x'를 생성하게 된다. 가우시안 분포가 가정되었기 때문에 생성된 결과물은 분포의 평균값으로 수렴하고, 그래서 VAE의 문제점으로 꼽히는 흐릿한 이미지가 생성된다. -> VAE에서 가우시안 말고 다른 분포를 사용한다면 흐릿한 이미지가 생성되는 문제를 해결할 수 있을까?
GAN: Generative Adversarial Network
GAN은 모델을 속이는 적대적 학습 방식(Adversarial training)을 사용하는 생성 모델로, Generator와 Discriminator 두 부분으로 구성된다.
Generator는 그럴싸한 데이터를 생성하고, Discriminator는 Generator의 결과물(가짜)와 실제 이미지를 구분하는 역할을 한다. 학습 초기에 Generator는 터무니없는 가짜 데이터를 생성해 Discriminator는 이를 쉽게 판별할 수 있겠지만, 학습이 진행될수록 Generator는 Discriminator를 잘 속일 수 있는 방향으로 개선될 것이다. 하지만 여기서 GAN의 근본적인 문제가 발생한다.
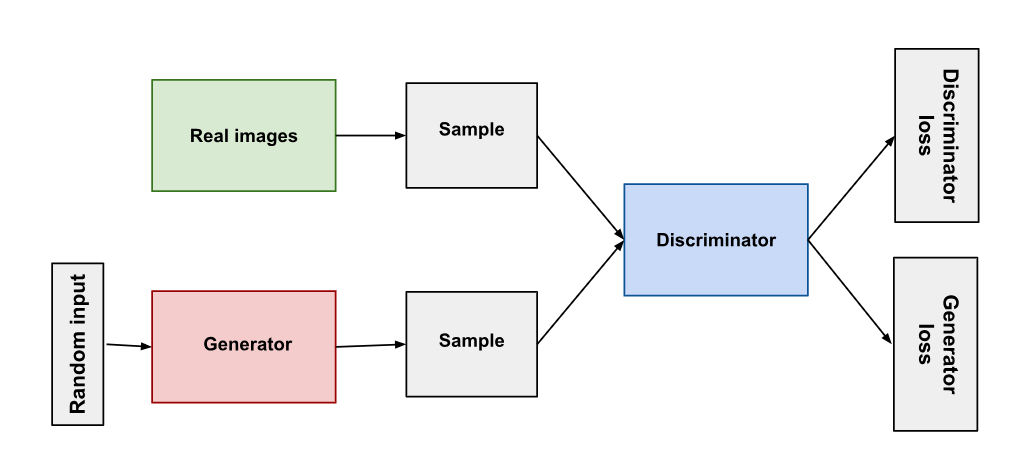
Generator와 Discriminator 두 가지가 함께 개선되기만 할 수 있다면 좋겠지만, 완벽하게 성공적인 Generator가 만들어질 경우, Discriminator는 50%의 정확성을 갖게 된다. 즉, Discriminator는 반반의 확률 에서 랜덤으로 추측하게 된다. 이러한 상황이 오면 GAN의 전체적인 수렴에 문제가 생기고, 에폭이 더 진행될수록 Discriminator의 진짜 or 가짜 예측의 의미가 저하된다.
또한, Discriminator를 잘 속이는 극히 소수의 경우만 생성하는 방향으로 Generator가 학습되는 등 불안정할 여지도 많아 GAN은 잘 학습시키기 어려운 모델로 여겨지고 있다. 그럼에도 불구하고 GAN은 이미지 생성 분야에서 다양하게 활용되고 있는 대표적인 모델이다.
->Why??
사전 지식
markov assumption
markov chain
KL divergence
Diffusion
Diffusion model은 data에 noise를 조금씩 더해가거나 noise로부터 조금씩 복원해가는 과정을 통해 data를 generate하는 모델이다.

이를 한 눈에 표현하면 위 그림과 같다. 위 그림에서 x_0는 실제 데이터, x_T는 최종 noise, 그리고 그 사이의 x_t는 데이터에 noise가 더해진 상태의 latent variable을 의미한다.
즉, diffusion model의 goal은 p_θ(x_0) =
위 그림의 오른쪽에서 왼쪽 방향으로 noise를 점점 더해가는 forward process를 진행하고, 그리고 이 forward process를 반대로 추정하는 reverse process를 학습함으로써 noise(x_T)로부터 data(x_0)을 복원하는 과정을 학습한다.
이 reverse process를 활용해서 random noise로부터 우리가 원하는 image, text, graph 등을 generate할 수 있는 모델을 만들어내는 것이다.
Diffusion 모델은 노이즈가 섞인 이미지에서 원래 이미지를 완벽하게 복원하는 것은 불가능하지만, 그와 비슷한 새로운 이미지를 만들어 낼 수 있다는 점을 활용한 모델이다. 초기 모델의 한계를 DDPM과 DDIM 두 모델이 극복해내면서 Diffusion 계열 모델들의 활용성이 커졌다.
DDPM: Denoisiong Diffusion Probabilistic Models
Diffusion 모델은 크게 Markov assumption과 정규분포를 기반으로 하며, 노이즈를 추가하는 Forward process q(x_1:T∣x_0)와 노이즈를 제거하는 Reverse process p_θ(x_0:T)두 단계로 이루어진 모델이다.
-> Markov assumption이란?
마르코프 가정(Markov assumption)이란 어떠한 시점의 상태는 그 시점 바로 이전의 상태에만 영향을 받는다는 가정이다.현재의 상태가 바로 이전 상태에만 영향을 받는다고 가정하는 것이 어떻게 보면 무리한 가정일 수 있으나 모든 과거를 고려하는 것은 현실적으로 불가능하다.
마르코프 가정은 아래와 같이 정의 된다.
-> Markov chain이란?
마르코프 체인은 '마르코프 성질'을 가진 '이산시간 확률과정' 이다.
마르코프 성질 - 과거와 현재 상태가 주어졌을 때의 미래 상태의 조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결정됨
이산시간 확률과정 - 이산적인 시간의 변화에 따라 확률이 변화하는 과정
(1) Forward Diffusion Process (q)

Forward Diffusion Process, q는 markov chain으로 data(x_0)부터 noise를 더해가면서 최종 noise(x_T) 형태로 가는 과정이다.(sampling의 반대 방향) 우리가 이 과정의 분포를 알아내야 하는 이유는, reverse process의 학습을 forward process의 정보를 활용해서 하기 때문이다.
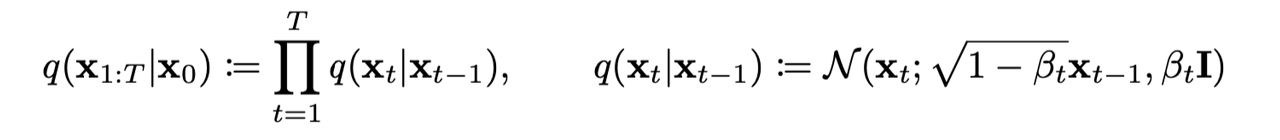
- data에 noise를 추가할 때, variance schedule을 이용하여 scaling을 한 후 더해준다.

- 매 step 마다 gaussian distribution에서 reparameterize를 통해 sample하게 되는 형태로 noise는 추가되는데, 이때 단순히 noise만을 더해주는게 아니라 1-B_t로 scaling하는 이유는 variance가 발산하는 것을 막기 위함이다.
(2) Reverse Diffusion Process (p)
Reverse Diffusion Process p 는 noise(x_T)로부터 data(x_0)를 복원하는 과정이다.
최종적으로 random noise로부터 data를 generate하는 generative model로 사용되기 때문에 diffusion model을 사용하기 위해서는 모델링하는 것이 필수적이지만, 이를 실제로 알아내는 것은 쉽지 않다.
-> 우리가 알고 싶은 건 q(x_t-1 | x_t)이나, 이를 알긴 어려움.
그러므로 우리는 p_θ를 활용해서 이를 approximate한다. 이 approximation은 Gaussian transition을 활용한 Markov chain의 형태를 가진다. 이를 식으로 표현하면 다음과 같다.

위 식에서, 각 단계의 정규 분포의 평균과 표준편차는 학습되어야 하는 parameter들이다. 그리고 위 식의 시작 지점인 noise의 분포는 다음과 같이 가장 간단한 형태의 표준정규분포로 정의한다.

DDPM은 여기서 variance를 아래와 같이 정의한다.

이로써 variance는 상수가 되고, 모델은 정규분포의 평균에 해당하는 만 학습하게 됨으로써 모델이 학습해야 할 파라미터의 범위를 또 한 번 줄인다.
(3) Objective Function (Loss Function)
- 이렇게 forward process와 reverse process가 무엇인지를 알았으니 이제 p_θ의 parameter 추정을 위해 diffusion model을 어떻게 학습을 하는지에 대해 알아보겠다.
- 앞서 언급했듯 실제 data의 분포인 p_θ(x_0)를 찾아내는 것을 목적으로 하기 때문에 결국 이의 likelihood를 최대화 (음의 likelihood를 최소화)하는 것이 우리가 원하는 목적이다. 이를 식으로 나타내면 다음과 같다.

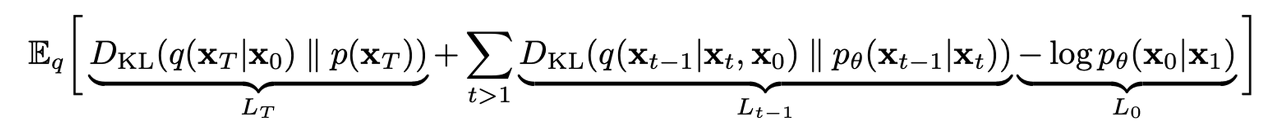
- 위 식에서 각각의 term이 가지는 의미를 살펴보면
- LT: p가 generate하는 noise(x_T)와 q가 x_0라는 데이터가 주어졌을 때 generate하는 noise(x_T)간의 분포 차이
- Lt-1: p와 q의 reverse / forward process의 분포 차이. 이들을 최대한 비슷한 방향으로 학습한다.
- L0: latent x1으로부터 data x0를 추정하는 likelihood. 이를 maximize 하는 방향으로 학습한다.
결론적으로, 우리가 diffusion model을 학습할 때의 training loss는 정규 분포 사이의 KL divergence 형태로 쉽게 계산될 수 있는 것이다.
DDIM: Denoising Diffusion Implicit Models
Diffusion 모델은 GAN에서 소개한 adversarial training 없이도 이미지를 잘 생성하고, DDPM은 위에서 소개한 방법으로 학습 파라미터를 줄여 개선을 이루어 냈다. 하지만 DDPM은 여전히 Markov chain에 따라 noising/denoising 작업을 진행하게 되고, 그렇기 때문에 매 step을 밟으며 모델을 학습하고 sampling을 해야해 여전히 시간이 오래 걸린다는 단점이 있다. 이를 해결하기 위해 DDIM이 소개되었다.
https://deepinsight.tistory.com/127
[정리노트] [AutoEncoder의 모든것] Chap4. Variational AutoEncoder란 무엇인가(feat. 자세히 알아보자)
AutoEncoder의 모든 것 본 포스팅은 이활석님의 'AutoEncoder의 모든 것'에 대한 강연 자료를 바탕으로 학습을 하며 정리한 문서입니다. 이활석님의 동의를 받아 출처를 밝히며 강의 자료의 일부를 인
deepinsight.tistory.com
https://aiconnect.kr/competition/detail/227/task/295/community/detail/158
AI CONNECT | AI Competition Platform
No.1 인공지능 경진대회 플랫폼
aiconnect.kr
https://jang-inspiration.com/ddpm-1
[논문리뷰] DDPM: Diffusion Model Background
Diffusion Model의 기본적인 개념과 Forward/Reverse Process, Loss Function 등에 대해 알아보자.
jang-inspiration.com
'ML DL' 카테고리의 다른 글
| 3D Representation 정리 (Mesh, Point Cloud, NeRF, 3D Gaussian) (4) | 2025.07.31 |
|---|---|
| [ ML/DL ] Loss function 왜 필요하고, 어디에 사용되는 걸까? (1) | 2024.03.23 |
| <Do it! 데이터 과학자를 위한 실전 머신러닝> 후기 (0) | 2023.08.31 |
| 분류모델 평가산식 정리(Accuracy, Precision, Recall, F1-score) (0) | 2023.06.29 |



